Medical-AI-Chatbot - Visual Studio Code





Built with production-grade RAG pipeline featuring hybrid retrieval, cross-encoder reranking, and cloud-native deployment on AWS infrastructure.
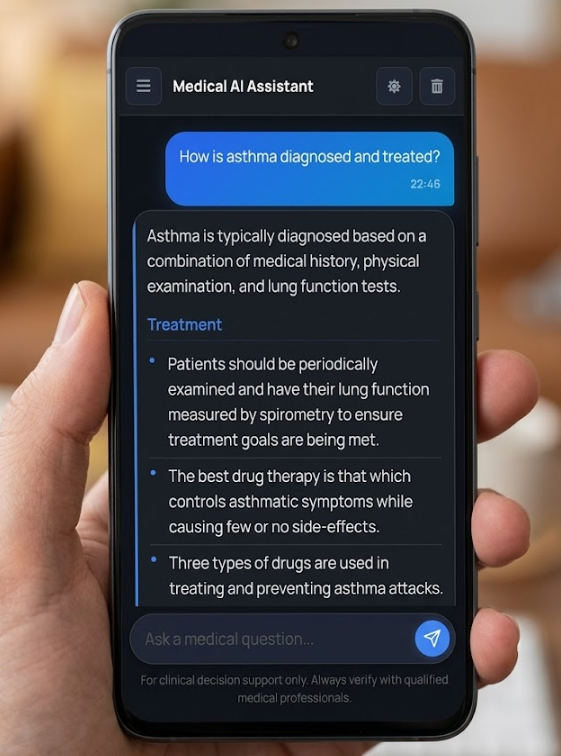
RAG-Powered Accuracy.
92% answer relevancy with source-grounded medical responses.
Hybrid Retrieval Pipeline
MMR + BM25 ensemble with cross-encoder reranking for precision.
AWS Cloud Deployment
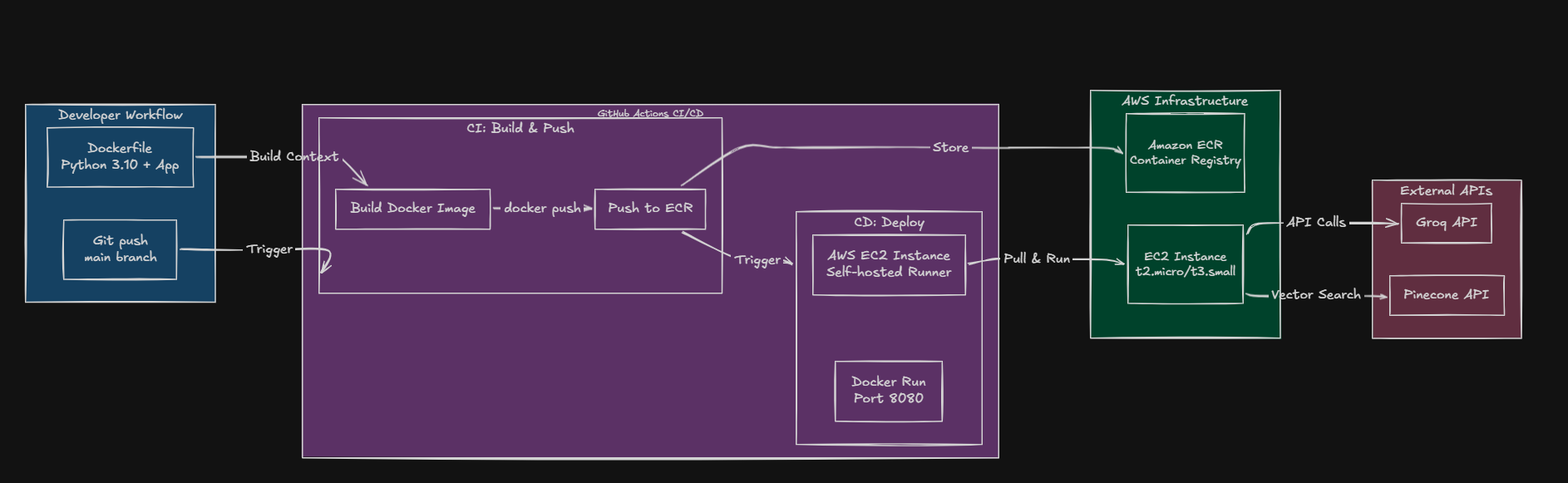
Docker containers on EC2 with GitHub Actions CI/CD pipeline.
Vector Search with Pinecone
384-dim embeddings for semantic medical document retrieval.
Llama 3.3 70B Generation
Context-only LLM responses with 88.7% faithfulness score.
Comprehensive Testing Suite
153 tests covering unit, integration, security, and performance.
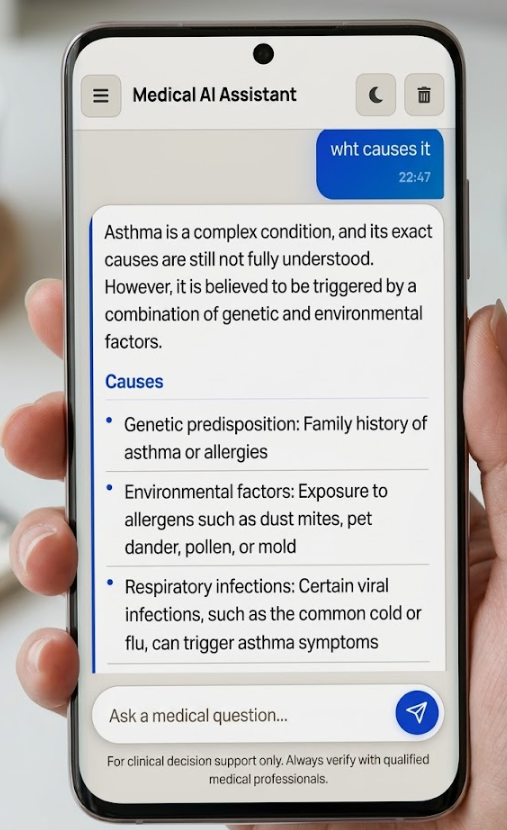
Beautiful, responsive interface with light and dark modes. Get evidence-based medical information with source citations.
Production-grade RAG architecture combining multiple retrieval strategies for maximum accuracy and relevance.
View on GitHubLlama 3.1 8B resolves pronouns and expands medical terminology for precise retrieval.
# Pronoun Resolution "What are its side effects?" → "What are the side effects of metformin?"
MMR (60%) + BM25 (40%) ensemble combines semantic understanding with keyword matching.
ensemble_retriever = EnsembleRetriever( retrievers=[mmr_retriever, bm25_retriever], weights=[0.6, 0.4] )
ms-marco-MiniLM-L-6-v2 scores query-document pairs for final relevance ranking.
reranker = CrossEncoder( "cross-encoder/ms-marco-MiniLM-L-6-v2" ) top_docs = reranker.rerank(query, docs, top_n=8)
Llama 3.3 70B generates responses strictly grounded in retrieved context.
system_prompt = """Answer ONLY from the provided context. If information is not in the context, say 'I don't have enough information to answer that.'"""
Optimized document segmentation preserves semantic coherence for medical content.
100-token overlap ensures context continuity
Maintains last 10 exchanges (20 messages) for pronoun resolution only.
Set to 0 for deterministic, factual medical responses without creativity.
Strict context-only mode reduces hallucinations from 35% to 5%.
Production-grade RAG pipeline with hybrid retrieval, cross-encoder reranking, and cloud-native deployment
GitHub Actions with Docker, ECR, and EC2 deployment
Llama 3.1 8B resolves pronouns and expands queries
MMR + BM25 ensemble (0.6/0.4 weights)
ms-marco-MiniLM-L-6-v2 selects top-8 docs
Llama 3.3 70B with context-only mode
Comprehensive documentation covering architecture, testing, deployment, and evaluation metrics
IEEE 830-1998 compliant SRS document covering functional and non-functional requirements, system architecture, and use cases.
Complete documentation of the Retrieval-Augmented Generation pipeline including document indexing, query processing, and response generation.
GitHub Actions workflow with Docker containerization, Amazon ECR registry, and automated EC2 deployment.
Comprehensive evaluation using the RAGAS framework measuring faithfulness, relevancy, precision, and recall metrics.
Complete test suite documentation covering unit, integration, security, performance, and system workflow tests.
Security vulnerability testing including XSS prevention, SQL injection protection, and API key security validation.
Everything you need to know about Medi-Query's RAG architecture and technical implementation